Prudence : document en construction, et structure en émergence...
Sur un processeur donné, un système multiprogrammé est, en général, plus lent qu'un système monoprogrammé de complexité équivalente réalisant une tâche semblable.
La raison de ce constat est que le système monoprogrammé ne se préoccupe pas de synchronisation de l'accès aux données partagées, et n'est pas ralenti par des changements de contexte lorsque le système d'exploitation passe d'un fil d'exécution à l'autre. Le modèle général proposé ici a été utilisé avec succès dans plusieurs systèmes à « haute performance », incluant des systèmes de simulation et des systèmes en temps réel.
Si la « performance » doit être à son maximum, et si le système à développer est le seul véritable propriétaire des ressources de l'ordinateur, il faut donc viser un système qui déploiera un fil d'exécution par processeur. Sur le plan architectural, cela peut être réalisé en concevant ce qu'on nomme un exécutif, donc un programme organisé de manière à ce que des tâches exécutées par étapes remplacent les fils d'exécution et soient prises en charge par un programme maître (l'exécutif) capable :
Un exécutif efficace offrira donc un fil d'exécution par processeur. Consquemment, les tâches d'un même fil d'exécution seront exécutées de manière récurrente mais pas en parallèle, ce qui élimine de facto la question de la synchronisation entre elles; si un exécutif comprend plusieurs fils d'exécution et si deux fils d'exécution distincts d'un même exécutif doivent communiquer, évidemment, le problème de la synchronisation resurgit automatiquement, alors on réduira au minimum (idéalement à néant) la communication entre fils d'exécution et on cherchera à la réaliser à des moments et à un rythme ciblés.
À titre de rappel, le polymorphisme dynamique (Late Binding) a un coût, mais ce coût est constant et mesurable (concrètement, on parle d'une indirection de pointeur par invocation), si nous escamotons la question de la gestion de l'antémémoire. Conséquemment, ce mécanisme est admissible dans un STR.
Le logiciel sous contrôle de l'exécutif sera découpé en tâches. Une tâche sera une classe dérivant d'une interface minimaliste connue de l'exécutif. Chaque tâche devra agir, de manière brève et linéaire si possible puisque toute tâche peut, si elle épuise le temps disponible, empêcher les autres tâches de s'exécuter.
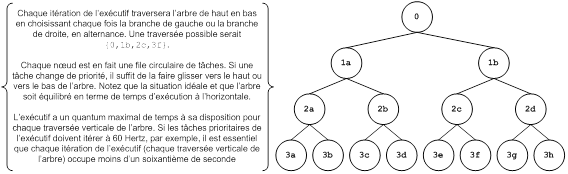
L'exécutif organisera les tâches selon une structure de priorités. Typiquement, on parlera d'un arbre binaire dont la racine est faite de la liste des tâches jugées critiques (qui doivent être exécutées à chaque itération de l'exécutif), les premières branches des tâches importantes (exécutées une itération sur deux, soit la branche de gauche une itération et la branche de droite à l'itération suivante). À chaque niveau subséquent, les tâches inscrites seront exécutées de un peu moins souvent, soit une itération sur quatre, une itération sur huit, une itération sur 16... et, de manière générale, à chaque itérations pour une tâche au niveau .
L'exécutif est responsable du respect des contraintes de « performance » du système. Suite à l'exécution de chaque tâche, il doit évaluer si le temps restant lui permet d'exécuter la prochaine tâche (au niveau courant dans l'arbre ou dans la prochaine branche à exécuter). Lorsque le temps restant pour l'itération en cours ne suffit plus, l'itération se termine et la prochaine tâche à exécuter sera le point où l'exécution reprendra lors du prochain passage de l'exécutif dans la branche où s'est interrompu le traitement.
Les exécutifs demandent de la calibration quelque peu manuelle des branches de tâches à exécuter, pour assurer le respect en tout temps des contraintes TR et, règle générale, pour assurer un certain équilibre de la consommation des ressources. On voit souvent les exécutifs prendre en charge des systèmes faits de tâches au comportement prévisible (dans le pire cas) et périodiques (la périodicité est en quelque sorte induite par le modèle même d'exécutif).
Certains exécutifs, les exécutifs périodiques statiques (sur lesquels nous reviendrons), ont des propriétés qui permettent de valider a priori leur comportement et la capacité de céduler leurs tâches dans le respect des contraintes de chacune.
Un point faible des exécutifs est qu'ils se prêtent moins bien à l'insertion de tâches imprévisibles; pour des STR comprenant des tâches apériodiques ou au comportement moins prévisible, des ordonnanceurs préemptifs à base de priorité sont typiquement privilégiés.
Pour partager les données entre les tâches sans savoir a priori lesquelles sont incluses ou non dans le modèle de données de l'exécutif, plusieurs options sont possibles, incluant des canaux un à un entre les tâches, des ardoises virtuelles où s'inscrivent des messages identifiés par catégorie ou par destinataires, mais toutes ces options sont lentes en comparaison avec un simple espace mémoire partagé et des variables identifiées à leur auteur par leur nom.
Conceptuellement, utiliser un bloc massif (probablement des dizaines de mégaoctets) de ce qui serait essentiellement des variables globales pour communiquer semble horrible. Ce l'est. Cependant, il faut considérer que nous discutons ici d'architecture spécialisée et orientée vers la « haute performance ». Procéder par partage de données comporte plusieurs avantages :
Les tâches et leurs besoins en termes de données étant ciblés et circonscrits, il devient relativement simple de décrire le processus d'intégration d'une tâche et des données qui l'intéressent au système.
Intégrer une tâche au système implique l'insérer dans l'arbre des tâches à un endroit approprié. Normalement, un individu (un spécialiste d'intégration) sera responsable de procéder à cette insertion et au bon fonctionnement du système (s'assurer qu'une tâche ne nuira pas à l'équilibre systémique et au respect des attentes de performance de l'exécutif, par exemple).
Par contre, les données tendent à être importantes et l'intégration d'une tâche au système implique presque par définition l'insertion d'un bloc de données globales, ce qui aura tendance à modifier la structure du segment de données global du programme. Pour cette raison, une recompilation du système entier sera coûteuse et devra être faite à des moments opportuns. Les diverses tâches devront avoir des environnements de développement bien à elles et les changements aux données globales devront être réduits à l'essentiel (si ça ne sert pas à communiquer avec d'autres tâches, alors ça ne vas pas là!).
Quelques liens pour enrichir le propos.
