Quelques raccourcis :
Merci tout spécial à mon ami et collègue Pierre Prud'homme, qui a pris le temps de dépister les nombreuses coquilles du premier jet en français de ce texte!
Une question en apparence banale, mais en pratique litigieuse, dans le Monde merveilleux de la programmation® est celle des extrants d'une fonction, à savoir :
La liste de questions ci-dessus n'est pas exhaustive, évidemment. Ce qui suit vise à donner une meilleure compréhension de cet enjeu, incluant une perspective historique, tout en évitant un argumentaire qui serait du ressort de la croyance.
Notez que, dans une perspective pédagogique, la réponse à la question « devrait-on permettre à une étudiante ou à un étudiant en programmation de placer plusieurs points de sortie – plusieurs return – dans une même fonction » peut avoir plusieurs réponses, en fonction du point où la question se pose dans le cheminement de formation de l'individu. Ce qu'on souhaite mettre en place comme réflexe chez des débutantes et des débutants peut différer des pratiques plus pragmatiques auxquelles on peut être ouverte ou ouvert face à des étudiantes ou à des étudiants plus avancés dans leur parcours.
Je ne vise donc pas ici une réponse dans l'absolu, mais bien un questionnement... Dans certains cas, même : une remise en question de mythes pour en arriver à une position plus éclairée. Je pense à la question des multiples points de sortie en particulier.
Plusieurs enseignent, ou ont enseigné, qu'il faut viser un seul point de sortie par fonction. Je suis d'ailleurs de ceux-là : c'est ce qu'on m'a appris, et c'est le principe que j'ai longtemps moussé (et que je mets encore de l'avant aujourd'hui dans bien des cas).
Cela dit, il est parfois sain de se demander d'où viennent certains principes que nous enseignons et que nous appliquons. Certains idées peuvent être valables à une époque, et être moins adaptées à une autre.
Le crédo selon lequel une fonction ne devrait avoir qu'un seul point de sortie est inspiré d'un texte d'Edsger W. Dijkstra, dans Notes on structured programming, que vous pouvez lire sur http://www.cs.utexas.edu/users/EWD/ewd02xx/EWD249.PDF. Mon ami Dan Saks, un sage, m'a toutefois informé que le texte d'Edsger W. Dijkstra a été précédé de quelques années par un texte, celui-là de Corrado Böhm et Giuseppe Jacopin : Böhm, C. and Jacopin, G., Flow Diagrams, Turing Machines And Languages With Only Two Formation Rules, que vous trouverez sur http://www.cs.unibo.it/~martini/PP/bohm-jac.pdf.
Tiré de cet article :
« […] every Turing machine is reducible into, or in a determined sense is equivalent to, a program written in a language which admits as formation rules only composition and iteration »
Dans https://crivelloappendini.wordpress.com/2012/10/05/the-theorem-of-bohm-jacopini/, qui pose un regard sur ce texte, on peut d'ailleurs lire :
« In fact [l'article] has contributed to the criticism of the injudicious use of the instructions go to is the definition of guidelines of structured programming that we have had around 1970 »
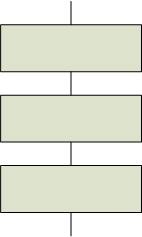
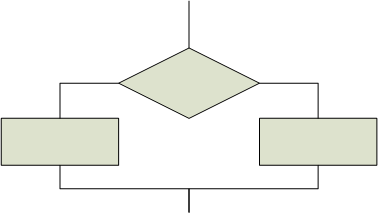
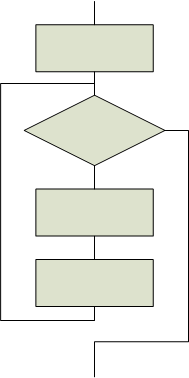
Informellement, à l'époque où ces textes ont été écrits, on oeuvrait à la formalisation des programmes. Dans un programme, une unité complexe (une fonction) était présentée comme composée d'unités plus simples; ces unités formaient une séquence d'opérations. Pour construire une telle séquence, chaque opération complexe devait avoir un seul point d'entrée et un seul point de sortie.
L'idée avancée dans ces textes est qu'il est possible de démontrer le bon fonctionnement d'un programme si celui-ci est construit à partir de séquences, d'alternatives et de répétitives, et de fonctions qui apparaissent comme des blocs complexes de ces trois éléments (et d'autres fonctions) ayant elles aussi un seul point d'entrée et un seul point de sortie.
| Séquence | Alternative | Répétitive |
|
|
|
|
Dans cette perspective, un programme est fait de fonctions qui constituent elles-mêmes des séquences composites :
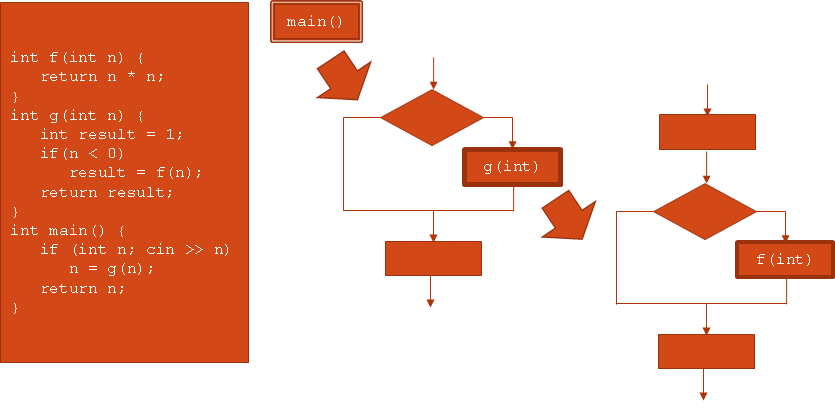
Vous trouverez un condensé de ces idées sur https://en.wikipedia.org/wiki/Structured_program_theorem.
L'idée de viser un seul point d'entrée et un seul point de sortie par fonction est un formalisme raisonnable, au sens où ce formalisme aide à raisonner sur le texte d'un programme structuré sur la base de sa forme. En ce sens, on pourrait tracer un parallèle avec l'enjeu (important!) de l'indentation.
J'utilise encore ces morphogrammes dans mon enseignement, surtout avec des débutantes et des débutants, car celles-ci et ceux-ci peinent parfois à voir en quoi leur algorithme manque un cas clé lorsqu'il comprend des alternatives imbriquées (des if imbriqués). Par exemple, si on prend une fonction devant trouver et retourner le plus petit de trois nombres, un algorithme incorrect possible (qui ne compile pas dans plusieurs langages, dû à une possible variable non-initialisée au point de sortie) serait :
| Pseudocode | C++ | C# |
|---|---|---|
|
|
|
Quand mes étudiantes et mes étudiants me proposent une telle solution, tracer le morphogramme de la fonction montre clairement qu'il est possible, par l'un des chemins, de ne jamais initialiser la variable utilisée pour contenir la valeur à retourner. Cette visualisation me rend de précieux services.
Toutefois, il n'est pas toujours pratique d'exprimer des algorithmes en se restreignant à une application stricte de ce formalisme.
Je ne propose donc pas un laxisme face au principe de viser un seul point de sortie par fonction. Comme pour bien des cas de « sagesse traditionnelle » les avantages de respecter ce principe sont nombreux. Je propose d'examiner les raisons pour lesquelles il s'agit d'un principe général, pas d'un dogme.
Plusieurs sommités de la programmation et du génie logiciel ont tenu des discours semblables au fil des années, mais avec quelques nuances. Parmi les sommités les plus connues, on trouve entre autres Steve McConnell, dans son livre Code Complete, ou Robert C. Martin, dans son livre Clean Code (que je n'ai malheureusement pas lu encore; ce n'est qu'une question de temps). Ce dernier aurait d'ailleurs, selon Waseem Senjer, écrit ceci :
« Some programmers follow Edsger Dijkstra’s rules of structured programming. Dijkstra said that every function, and every block within a function, should have one entry and one exit. Following these rules means that there should only be one return statement in a function, no break or continue statements in a loop, and never, ever, any goto statements.
While we are sympathetic to the goals and disciplines of structured programming, those rules serve little benefit when functions are very small. It is only in larger functions that such rules provide significant benefit.
So if you keep your functions small, then the occasional multiple return, break, or continue statement does no harm and can sometimes even be more expressive than the single-entry, single-exit rule. On the other hand, goto only makes sense in large functions, so it should be avoided. »
Ceci annonce une vision un peu plus pragmatique que celle à laquelle on aurait pu s'attendre, même par des tenants de code dit « de qualité ».
Viser un seul point de sortie est souvent une bonne idée. Prenons pour exemple un cas à la fois simple mais typique de situations pour lesquelles la paresse pourrait mener certaines ou certains à utiliser plusieurs points de sortie pour une même fonction, sans qu'il n'y ait de réels avantages.
Par exemple, la version naïve qu'une étudiante ou un étudiant en début de parcours pourrait proposer pour cette fonction utiliserait une variable temporaire, déterminerait sa valeur à partir d'une alternative, et retournerait le résultat ainsi calculé. Cette version, bien que valide, est longue et les diverses étapes de son implémentation n'apportent ni un avantage technique, ni une sémantique plus claire que ne le ferait une version plus concise. |
|
Une autre version un peu moins longue serait celle-ci. Encore une fois, ici, la restriction à un seul point de retour et la séquence d'opérations qui mènera au calcul du résultat retourné n'apporte pas d'avantage évident (il y a beaucoup de bruit, d'éléments inutiles dans cette fonction, et ce bruit obscurcit le propos sans apporter d'avantage technique). |
|
Certaines ou certains pourraient plaider pour une version avec deux points de sortie. Dans ce cas, ce pourrait être légèrement plus rapide que les deux versions précédentes, mais nous faisons preuve de laxisme en utilisant une alternative pour exprimer l'idée que si la condition évaluée par l'alternative s'avère, nous retournerons true alors que si elle ne s'avère pas, nous retournerons false... |
|
... la version la plus directe, après tout, n'a qu'un seul point de sortie et est à la fois plus simple et (probablement) plus rapide. Avec un bon optimiseur, pour des types primitifs, le code généré pour ces diverses fonctions devrait être équivalent. En présence de surcharge d'opérateurs, l'enjeu est différent, et mieux vaut prendre le meilleur algorithme du lot... qui est aussi le plus simple! |
|
Visiblement, il ne faut pas voir une ouverture à la discussion sur le recours raisonné et pertinent aux multiples points de sortie dans une fonction comme une permission accordée pour s'adonner à une programmation laxe et inefficace.
Un cas intéressant pour illustrer l'intérêt de permettre le recours aux multiples points de sortie est la sortie hâtive d'une fonction dans le cas où le résultat d'un calcul est connu avant la fin du parcours d'un substrat.
|
|
Ce cas faisait partie de l'argumentaire de Donald E. Knuth a mis de l'avant en réponse au texte d'Edsger W. Dijkstra dans Structured Programming with go to Statements, dont l'introduction contient ce qui suit :
« […] This study focuses largely on two issues: (a) improved syntax for iterations and error exits, making it possible to write a larger class of programs clearly and efficiently without go to statements; (b) a methodology of program design, beginning with readable and correct, but possibly inefficient programs that are systematically transformed if necessary into efficient and correct, but possibly less readable code. The discussion brings out opposing points of view about whether or not go to statements should be abolished; some merit is found on both sides of this question »
Les caractères gras sont de moi.
Il y a plusieurs bonnes raisons d'essayer d'en arriver à un point de sortie unique par fonction. Entre autres choses, cela peut nous épargner de vilains bogues.
Prenons par exemple le court programme proposé à droite. Le programme utilise une énumération à trois valeurs, et couvre les trois valeurs dans une sélective (switch). On serait tenté de penser que le programme est robuste (et affichera Green dans ce cas bien précis), mais on oublierait alors :
D'ailleurs, la plupart des compilateurs C++ donneront un avertissement ici, et il sera justifié. Dans d'autres langages, on aura souvent une erreur. Les étudiantes et les étudiants qui débutent pensent parfois avoir trouvé un bogue de compilateur... Eh non, c'est bel et bien une erreur dans le programme. |
|
Comment régler cet irritant? Plusieurs options sont possibles, même en conservant le point de sortie unique.
|
Un correctif possible serait de retourner une valeur sentinelle par défaut. Ce n'est pas ce que je privilégierais, personnellement, car cela rend plus complexe le traitement des erreurs (distinguer cette valeur sentinelle des valeurs correctes demande un effort dans le code client, ce qui accroît les risques d'erreurs), mais c'est une option. Ici, cette option a toutefois un coût, soit l'initialisation (probablement redondante) de la variable contenant la valeur de retour. C'est embêtant de pessimiser l'exécution de chaque appel de fonction pour éviter un bogue dans un cas dégénéré... |
|
|
On pourrait aussi changer la signature et retourner un optional<T> (ici, T est string_view). et payer l'initialisation de l'objet vide qui sera retourné si c est hors-bornes... |
|
|
...ou encore lever une exception dans le cas où la valeur de c est hors-bornes, mais cela ne change pas fondamentalement le propos. Dans tous les cas, préférer un point de sortie unique entraîne un coût. Notez qu'ici, la levée d'exception est déjà un point de sortie alternatif... |
|
Si on sacrifie le point de sortie unique, toutefois, il devient possible de couvrir tous les cas (à travers un cas default dans ce cas-ci) tout en épargnant les coûts additionnels qui découleraient de l'initialisation d'un état par défaut :
| Retourner une valeur par défaut | Retourner un optional<T> | Lever une exception |
|---|---|---|
|
|
|
Évidemment, on peut en arriver à un seul point de sortie en remplaçant la sélective par un tableau :
enum class Color : size_t { Red, Green, Blue };
auto f(Color c) {
static const string_view names[]{ "Red"sv, "Green"sv, "Blue"sv };
return static_cast<size_t>(c) < size(names)?
names[static_cast<size_t>(c)] : throw 3; // peu importe
}Un bon truc pour réduire le nombre de points de sortie dans une fonction est, simplement, d'écrire de plus petites fonctions. Viser l'adage selon lequel à chaque fonction, on souhaite une seule et unique vocation. C'est d'ailleurs un idéal qu'il vaut la peine de poursuivre, du moins si votre compilateur est capable d'optimiser les appels de fonctions en réalisant du inlining (c'est plus difficile dans certains langages, mais en C++ l'écriture de petites fonctions peut se faire essentiellement à coût nul).
Ce n'est toutefois pas toujours trivial à réaliser.
Examinons par exemple ce prédicat classique, is_leap_year(), qui prend en paramètre une année et s'avère seulement si cette année est bissextile. Nous avons à droite un cas de point de sortie unique, de vocation unique, mais où l'algorithme doit couvrir plusieurs cas particuliers. Cette fonction, dans sa forme, ressemble à un diagramme. Elle en a d'ailleurs les qualités : plusieurs chemins peuvent être suivis, les conditions des branchements comprennent des dépendances et doivent être testés dans l'ordre, la variable result est inévitablement initialisée dans l'une des branches (le else à la toute fin en fait foi), et on n'y trouve qu'un seul point de sortie. Il n'est pas simple de l'analyser malgré tout : vérifier qu'elle est correcte demande un certain effort. |
|
Pour une écriture alternative, un peu plus simple à analyser et toujours limitée à un seul point de sortie, celle proposée à droite prend l'option pessimiste (false par défaut), puis se rétracte si un test subséquent démontre que ce pessimisme était mal avisé. Cette version me semble plus simple à analyser, mais elle comprend une initialisation potentiellement inutile. C'est embêtant de payer en vitesse pour gagner en lisibilité... Notez que certains langages vous font payer systématiquement pour les initialisations inutiles; ceci peut vous irriter ou pas, en fonction de vos besoins et des contraintes auxquelles vous êtes assujetti(e)s. |
|
Reprendre la première version, mais en éliminant la variable result, ne simplifie que très peu le raisonnement. La raison pour ce faible gain de lisibilité est que la structure des alternatives imbriquées demeure complexe. Conceptuellement, chacun des if après le premier se trouve dans le else du précédent, et la disposition superficiellement linéaire du code masque cette complexité inhérente. Une écriture plus honnête serait : ... ce qui est moins attirant, mais plus révélateur. La même réécriture devrait d'ailleurs être appliquée au premier exemple de la séquence, qui a précisément la même structure que celui-ci. |
|
|
En fait, pour vraiment simplifier l'algorithme, l'idéal ici est de faire ce que d'aucuns nomment du « code communiste », au sens où il « penche à gauche » : réduire les niveaux d'imbrication, en sortant de la fonction dès que la réponse est trouvée, et en simplifiant du même coup la structure dans son ensemble. L'exemple à droite illustre cette pratique. Le résultat est plus facile à analyser, et il n'y a pas de coût supplémentaire. |
|
Notez que dans ce cas, il serait possible de réduire à fonction à un seul return, mais l'expression booléenne exprimant la valeur à retourner serait difficile à analyser et il n'est pas clair que nous gagnerions au change.
Dans les langages où on manipule directement des objets (ce qui inclut C++, mais exclut Java ou C# par exemple), ou encore dans les langages où les objets sont instanciés dynamiquement et manipulés indirectement (Java ou C# par exemple, et C++ de manière occasionnelle) et où on souhaite retourner une référence sur un objet instancié dans tous les cas, le coût des constructeurs est à considérer.
Prenons un exemple comparatif en C# et en C++ pour fins d'illustration (l'équivalent Java est conceptuellement identique à la version C# avec des différences cosmétiques). La version C# utilisera une hiérarchie de deux classes et des mécanismes idiomatiques de ce langage (pour cet exemple, on aurait aussi pu utiliser le Pattern Matching), et la version C++ utilisera variant ce qui est idiomatique des pratiques contemporaines dans ce langage.
| Version C# | Version C++ | |
|---|---|---|
|
De part et d'autre, nous rendons disponibles les outils standards que nous utiliserons. Les différences en termes de nombre d'outils tiennent à trois grands facteurs :
|
|
|
|
Dans notre exemple, les messages sérialisés seront précédés d'un entier indiquant à quel type de message ils appartiennent. Ceci permettra d'instancier le bon type lors de la désérialisation. J'ai utilisé des énumérations (en C#, en C++) avec substrat 16 bits non-signé dans les deux cas. Notez que le code C++ infère le type de substrat à l'aide de traits lors de la consommation, alors que le code C# implique un transtypage manuel, ce qui alourdit un peu l'entretien du code en pratique. Notez aussi que les erreurs lors d'accès sur un flux en C# lèvent une exception. En C++, les erreurs d'entrée/ sortie ne sont pas considérées exceptionnelles, et le flux peut être testé comme un booléen pour valider le succès ou l'échec d'une telle opération. |
|
|
|
La situation est analogue pour la sévérité des avertissements. |
|
|
|
Puisque l'exemple utilisera des chaînes de caractères contenant potentiellement des espaces, j'utiliserai std::quoted en C++ car ce mécanisme gère à la fois les espaces et les guillemets imbriqués. Ne connaissant pas le mécanisme équivalent en C#, j'irai de manière très naïve avec des outils simplistes (à droite) qui allouent des ressources et ne traitent pas correctement les guillemets imbriqués. De même, j'insérerai systématiquement des guillemets autour des chaînes de caractères sérialisées pour alléger l'exemple. La version C# est donc un peu plus naïve que la version C++ en ce sens. |
|
|
Le code C# est aussi plus simple (mais beaucoup plus coûteux) pour ce qui est des entrées/ sorties. Vous avez peut-être remarqué, plus haut, que le code C++ définit des opérations d'entrée et de sortie pour les énumérations, alors que le code C# ne se préoccupe que des entrées; c'est que le code client en C# fera des transtypages explicites en ushort ou en string pour fins d'affichage, alors que les types C++ sont complets et gèrent eux-mêmes ces opérations.
La prépondérance (coûteuse) des conversions en string et des dépendances explicites envers les substrats des énumérations est idiomatique de langages comme C# et Java, mais ne sont pas adéquates en C++ où les coûts inutiles sont mal vus, et mal venus.
Pour cette raison, vous remarquerez (ci-dessous) que dans le code C#, j'ai intégré le type de message à la string construite, ce qui évite une coûteuse opération, alors qu'en C++ le type de message est externe au message sérialisé et fait partie du code général de sérialisation.
Détail : en C++, il est simple de lire les données jeton par jeton (il serait aussi simple de le faire ligne par ligne, mais quel serait l'intérêt?). En C#, c'est beaucoup plus facile de procéder ligne par ligne, surtout en présence de chaînes de caractères comportant des espaces. Ceci explique que les formats utilisés pour les entrées/ sorties soient un peu différents dans les deux exemples.
| Version C# | Version C++ | |
|---|---|---|
|
Les deux versions utiliseront des types distincts pour les messages d'information (MsgInfo), les messages d'avertissement (MsgWarning) et les messages tout court (Message). La version C++ a ce défaut de demander un constructeur par défaut pour permettre les entrées/ sorties standards (on pourrait corriger cet irritant, mais cela compliquerait le propos). La version C# a pour sa part une gestion trop naïve du texte (on pourrait corriger cet irritant, mais cela compliquerait le propos), et repose sur une conversion coûteuse en string pour la sortie sur un flux. |
|
|
|
La procédure est essentiellement la même pour les messages d'avertissement que pour les messages d'information. Notez que j'ai utilisé struct en C++ mais pas en C#. Le mot struct n'a pas du tout le même sens dans les deux langages :
|
|
|
|
Une autre différence entre les deux approches est que j'aurai besoin explicitement d'un type de message représentant un message inconnu en C#, alors qu'il sera implicite (type monostate de variant) en C++ Cela est dû à la différence entre les deux approches appliquées pour résoudre le problème (hiérarchie de classes en C#, variant en C++). |
|
|
|
En C++, pour mon utilisation de variant, je réaliserai une visite à partir de plusieurs expressions λ. Si le code à droite vous semble obscur, ce qui serait compréhensible, vous pouvez me contacter. C'est une petite perle très pratique, facile à utiliser, mais difficile d'approche. |
|
C'est à partir de ce point que nous pouvons commencer à examiner les impacts de se retreindre à un seul point de sortie sur la conception des programmes.
Dans les deux langages, nous voulons qu'une instance de Message contienne soit un MsgInfo, soit un MsgWarning (il pourrait y avoir d'autres types de messages, bien sûr).
| Version C# | Version C++ | |
|---|---|---|
|
Dû à notre implémentation restreinte à un seul point de sortie, et au choix de ne pas recourir à null en C# comme valeur sentinelle pour indiquer un type de message non reconnu, il nous faudra une classe Message ayant un cas « par défaut », même si conceptuellement, il ne devrait pas y avoir de Message par défaut ici (quel serait le sens d'un tel message?). La version C# du code conserve une référence sur un object en tant que propriété car (a) nous n'aurons besoin que de ToString, qui est polymorphique à partir de object, et (b) les constructeurs de Message empêchent de passer des types inappropriés en paramètre à la construction de ce type. Si nous avions eu besoin que nos types de messages offrent plus de services que ToString, il aurait fallu, de manière intrusive, injecter un parent (interface ou classe) aux divers types de messages possibles et garder une référence sur ce parent en lieu et place de object. La version C++ du code utilise un variant, qui signifie « un type parmi les suivants ». Vous noterez que, comme pour le type par défaut de message en C#, le fait que nous nous restreindrons à un seul point de sortie en C++ nous forcera à créer un Message par défaut. Pour réduire les impacts de ce choix, nous utilisons un monostate comme premier type; cette classe vide est triviale à construire, ce qui réduit les impacts négatifs sur le temps d'exécution. Toutefois, il est agaçant d'introduire ce type dans notre design, car nous ne devrions pas en avoir besoin : comme nous l'indiquions plus haut, quel est le sens d'un message par défaut? On le constate déjà : dans un langage OO, se restreindre à un seul point de sortie dans une fonction peut impacter négativement la qualité de la conception. Nous vivons cette tare conceptuelle dans les deux langages, mais de manière un peu différente. Notez que le code C# passera par une string temporaire pour fins d'affichage, ce qui sollicitera la conversion polymorphique (par object). En C++, la projection d'un Message sur un flux se fera en visitant l'objet. |
|
|
|
Lire un message dans les deux langages est l'autre partie de notre code qui est fortement impacté par la restriction à un seul point de sortie. Dans la version C#, nous utilisons une référence sur un Message initialement inconnu, que nous faisons par la suite référer au type de message réellement consommé. Cette initialisation à un message inconnu pourrait dans ce cas-ci être remplacée par une initialisation à null accompagnée d'un cas default (avec break obligatoire, car C#...). Dans la version C++, nous utilisons un variant vide (monostate) par défaut, que nous remplaçons par la suite par un message du type effectivement consommé. Dans les deux cas, ceci déplace le fardeau du constat d'une erreur de lecture sur les épaules (virtuelles) du code client. |
|
|
|
Pour sérialiser des messages destinés à être désérialisés, j'utilise dans les deux cas un flux représenté en mémoire. Dans ces flux seront sérialisés des messages, et ces messages seront désérialisés ultérieurement. Voir ../TrucsScouts/flux_sur_texte.html pour plus d'informations sur cette technique. |
|
|
|
Enfin, les programmes de test consomment les messages sérialisés et les projettent à la console. |
|
|
À l'affichage, nous obtenons ce qui suit (même contenu de part et d'autre, mais des formats un peu différents dû aux forces et faiblesses des deux langages) :
| Version C# | Version C++ |
|---|---|
|
|
En quoi décider de ne pas se restreindre à un seul point de sortie (en sachant que nous contrevenions déjà à cette « règle » dans les fonctions de lecture, de toute manière) améliorerait-il notre design? Voici :
| Version C# | Version C++ | |
|---|---|---|
|
En acceptant plusieurs points de sortie par fonction, nous pouvons créer les objets à retourner au point où nous sommes prêts à le faire. Ceci nous permet de nous débarrasser des états par défaut, qui étaient des palliatifs un peu boiteux pour notre choix structurel. Il faudra toutefois trouver une approche pour représenter le cas où la lecture a échoué. |
|
|
|
Dans le code C#, j'ai conservé le choix de retourner null si le flux est épuisé, ceci n'étant pas techniquement une erreur, et j'ai levé une exception dans le cas où le type de message consommé du flux est inconnu. Une alternative aurait été une forme de TryParse retournant un booléen et acceptant le Message en paramètre sortant (out). Notez par contre que la sémantique des paramètres out en C# aurait obligé d'écrire dans ce paramètre, que l'opération ait réussi ou pas, ce qui aurait été contre-productif pour nous. Dans le code C++, j'ai changé le type de retour de Message à optional<Message> (il faut donc inclure <optional> pour compiler cette version), et j'ai évité complètement la construction d'un objet par défaut, outre dans le cas où le type consommé du flux est inconnu, dans quel cas un optional vide modélise une erreur de lecture. |
|
|
|
Le code de test C# n'a pas changé, bien qu'on pourrait l'adapter pour tenir compte des erreurs de lecture si tel était notre souhait. Le code C++ est légèrement modifié, au sens où le optional retourné est testé pour vérifier le succès (ou pas) de la lecture, et où sa valeur est affichée. |
|
|
L'affichage demeure le même. Notez que, pour la conception de notre système :
| Un seul point de sortie | Plusieurs points de sortie |
|---|---|
|
S'imposer un seul point de sortie signifie devoir tenir compte d'un état par défaut pour un type pour lequel un tel état n'est pas nécessairement pertinent |
Accepter plusieurs points de sortie permet de ne tenir compte que des états pertinents d'un objet, ce qui peut être un atout quand un type n'a pas d'état par défaut naturel |
|
S'imposer un seul point de sortie signifie déclarer et initialiser une variable avant d'être vraiment prêt à la construire |
Accepter plusieurs points de sortie permet de déclarer et initialiser une variable au moment où nous sommes vraiment prêts à la construire |
|
Le coût de la construction d'un état par défaut n'est pas nul, même si on n'a qu'à initialiser une référence ou un pointeur à une valeur nulle |
Éviter les constructions inutiles est un gain net. Éviter de modifier un design pour introduire un état qui n'y est pas naturel est un gain plus important encore |
De plus, objectivement, il existe des cas où de multiples points de sortie mène à du code plus simple. Réexaminez les exemples ci-dessus si vous n'en êtes pas convaincu(e)s.
Les extrants privilégiés d'une fonction passent par sa valeur de retour, mais le portrait général des extrants d'une fonction est plus complexe. Certaines fonctions n'ont pas d'extrant au sens du code (mais ont souvent des effets de bord); d'autres ont plusieurs extrants, exprimés à travers des valeurs de retour composites, par des paramètres sortants, ou par une combinaison des deux.
Une question propre aux extrants est celle de savoir si une fonction devrait toujours avoir (au moins) un extrant, quand bien même ce ne serait que pour signifier au contexte appelant que le calcul réalisé s'est bien complété (ou pas). Après tout, en mathématiques, une fonction a toujours un extrant.
Certains pourraient être tentés de mentionner les programmes principaux dans plusieurs langages commerciaux. Par exemple, en Java, main() est void, et en C#, Main() est void. Dans ces langages, la complétion de l'exécution d'un programme principal est considérée comme un succès, du moins par défaut, et il est possible de signaler une complétion incorrecte en appelant exit() en Java et Exit() en C#.
| En Java | En C# |
|---|---|
|
|
En C++, main() n'est jamais void, et les compilateurs qui supportent void main() ne sont pas conformes au standard. En C++, toutefois, main() a la particularité de retourner implicitement zéro (succès) si aucun return n'y apparaît.
Il y a donc mensonge à la fois dans les langages qui font du programme principal une fonction sans extrant (car, en pratique, ces fonctions retournent un signal de succès d'exécution au système d'exploitation), et dans les langages qui permettent d'omettre la valeur de retour et signalent un succès jusqu'à preuve du contraire. Ce qui est clair, cela dit, est qu'un programme principal n'est pas un bon exemple de fonction sans extrant... C'est une créature étrange et spéciale.
Il se trouve qu'en pratique, il y a des cas raisonnables de fonctions sans extrants. Par exemple :
| Avec répétitive while | Avec répétitive for |
|---|---|
|
|
Dans cet extrait (simpliste) de programme, nous avons deux fonctions sans extrants (type de retour void, pas de paramètre sortant), soit afficher_menu() et traiter_choix(). Il serait bien sûr possible de faire en sorte que ces fonctions retournent quelque chose (par exemple, un code de succès, ou un descriptif génrique de l'état du traitement qui a été fait), et cela peut même être une bonne idée dans certains cas, mais il est aussi raisonnable de présumer que afficher_menu() ne fait qu'afficher un menu, et que traiter_choix() fasse une tâche qui ne nécessite pas que l'on porte attention à son succès (ou pas).
De manière générale, toutefois, une fonction sans extrant (et, à plus forte raison, une fonction sans extrant et sans intrant) est un code malodorant... un Bad Code Smell. En effet, une fonction ayant une telle signature dépend nécessairement (a) d'états globaux ou partagés, ou encore (b) d'effets de bord.
On m'a d'ailleurs posé plusieurs fois cette question : « Pourquoi une surabondance de fonctions void est-elle un problème [à tes yeux]? » (à plus forte partie, une surabondance de fonctions void sans paramètres!).
Puisque la question est récurrente, voici quelques-unes des raisons :
En résumé, qu'une fonction soit de signature void F() implique que ses postconditions sont couplées au contexte, réduisant drastiquement la réutilisabilité du code. C'est souvent du code jetable... Si votre code comprend de telles fonctions, cela ne veut pas dire qu'il est mauvais, mais cela signifie toutefois qu'il peut être sage de le revisiter, et de se demander s'il est bien organisé, bien découpé. Retenez que si les postconditions de vos fonctions modifient des attributs d'un objet, votre code est peut-être fragile – c'est essentiellement comme si vous dépendiez de variables globales.
Rappelons brièvement que, bien que certains extrants soient des points de sortie d'une fonction (un return, par exemple, ou la plupart des throw), plusieurs extrants n'en sont pas. Ceci est particulièrement vrai pour les langages qui acceptent des paramètres sortants (passés par référence en C++, ou encore ref en C# – car les out sont des sortants purs).
Les exemples les plus connus d'extrants qui ne sont pas des points de sortie sont les paramètres de fonctions clés comme std::swap() ou std::exchange() en C++, ou encore la valeur consommée par un TryParse() en C# :
| Exemple avec std::swap() | Exemple avec std::exchange() | Exemple avec TryParse() |
|---|---|---|
|
|
|
Il existe aussi des langages, par exemple les langages Pascal et Modula, où ce qui tient lieu de « return » s'exprime en affectant au nom de la fonction en cours d'exécution la valeur de retour courante, ce qui ne complète pas l'exécution de cette fonction. Par exemple :
program demo_facto;
function factorielle(n : integer) : integer;
var i : integer;
begin
i := 1;
factorielle := 1;
while i <= n do
begin
factorielle := factorielle * i;
i := i + 1;
end;
end;
begin
writeln(factorielle(5));
end.Ceci répond d'ailleurs à la question « est-il raisonnable pour une fonction d'avoir plusieurs extrants? » : certains traitements ont conceptuellement besoin de deux extrants, et la fonction de permutation des états de deux paramètres en est sans doute le cas le plus exemplaire.
De manière générale, il est plus facile de raisonner sur la base de fonctions pures, au sens de fonctions qui acceptent des intrants par valeur, réalisent un calcul, et produisent un résultat en sortie à travers une valeur de retour. Ce mode de pensée est difficile à atteindre quand les paramètres sont des indirections vers des objets mutables et quand un programme est multiprogrammé; conséquemment, dans les langages qui ne supportent pas les accès directs aux objets (Java, C# et plusieurs autres; même C et C++ si vous passez les paramètres par référence ou par adresse), privilégiez les objets immuables, particulièrement si votre programme utilise plus d'un fil d'exécution.
Une fois cette mise en garde faite, règle générale, si vous avez le choix, préférez les fonctions qui profitent du mécanisme de valeur de retour pour exprimer leurs extrants. Quelques exemples, exprimés dans divers langages contemporains (vous pouvez extrapoler l'équivalent de chacun dans votre langage de prédilection) :
| Langage | À éviter | À préférer |
|---|---|---|
|
|
|
|
| |
|
|
Il est arrivé par le passé, particulièrement en C++, que des programmeuses et des programmeurs expérimenté(e)s estiment préférable d'utiliser la version de gauche, même si elle est moins claire et moins élégante, pensant s'épargner une copie de variable (copie qu'elles ou ils estimaient parfois coûteuse; ici, on parle que quelques mégaoctets de mémoire à copier et d'une allocation dynamique de mémoire non-négligeable). Cependant, depuis C++ 11 et l'avènement du mouvement, et à plus forte partie depuis C++ 17 qui garantit que tous les compilateurs conformes implémentent l'optimisation RVO, cette vision est incorrecte. Le code de droite est à la fois plus élégant, plus clair et plus rapide.
Il existe quelques cas où des paramètres sortants sont à privilégier. On peut penser à la permutation de deux valeurs :
| Exemple en C# | Exemple en C++ |
|---|---|
|
|
... notez l'absence d'exemple en Java, qui ne supporte que le passage de paramètre par valeur et ne permet donc pas l'implémentation de cet algorithme fondamental.
Un autre cas est celui où une fonction a plusieurs extrants. Par exemple, en C#, on trouve des méthodes TryParse pour divers types. Ces méthodes doivent rapporter à la fois le succès (ou pas) de la conversion d'une chaîne de caractères en un autre type, de même que le fruit de cette conversion si elle a réussi :
// ...
class Program
{
static void Main()
{
if (int.TryParse(Console.ReadLine(), out int n))
Console.WriteLine($"Entier lu : {n}");
else
Console.WriteLine("Erreur de lecture");
}
}L'équivalent C++ serait :
// ...
int main() {
if (int n; cin >> n)
cout << "Entier lu : " << n << endl;
else
cerr << "Erreur de lecture\n";
}... où on peut remarquer, conceptuellement, deux « extrants », soit la valeur lue (l'entier n), mais aussi le flux sur lequel la lecture a été faite, qui se comporte comme un booléen vrai seulement si l'opération de lecture fut un succès.
Il est aussi possible, dans plusieurs langages contemporains, de retourner plusieurs valeurs d'une même fonction et de les récupérer élégamment au point d'appel. Par exemple :
| Langage | Exemple |
|---|---|
En Go, il est idiomatique de retourner plusieurs valeurs d'une fonction. Au point d'appel, le code client peut ignorer une valeur de retour en utilisant _ à titre de nom de variable. |
|
En Python, retourner plusieurs valeurs d'une fonction est simple du fait que « déstructurer » des objets est une opération native du langage (permuter deux valeurs x et y s'exprime x,y = y,x tout simplement, ce qui est joli... et un peu trop magique pour qui souhaiterait apprendre la programmation avec ce langage). |
|
En C#, retourner plusieurs valeurs d'une même fonction se fait typiquement avec des uplets. La décomposition de la valeur de retour, si elle est souhaitée, se fait au point d'appel, sinon les éléments de l'uplets sont nommés Item1, Item2, ... C# permet aussi de nommer les membres d'un uplet pour aider à la documentation. Ici, le type de retour de DivEnt pourrait s'écrire (bool ok,int quot) si les noms Item1, Item2, ... suppléés par défaut ne sont pas souhaités. |
|
En C++, avec C++ 11, il était possible de modéliser une fonction ayant de multiples valeurs de retour à l'aide d'un uplet (std::tuple), dont std::pair peut être vu comme un cas particulier assez fréquent pour mériter son propre nom. Il est possible de déstructurer un std::tuple en utilisant la fonction std::tie(). Les éléments à ignorer peuvent l'être en utilisant std::ignore. |
|
En C++, depuis C++ 17, les Structured Bindings permettent de déconstruire un agrégat en ses parties constituantes. Ajoutez à cela CTAD, qui allège l'expression des types génériques, de même que les nouveaux if qui combinent initialisation et test, et le code client devient nettement plus agréable à exprimer. |
|
L'idée selon laquelle une fonction devrait se limiter à un seul point de sortie est une bonne idée, et on devrait tendre en ce sens, surtout dans l'enseignement de la programmation aux débutantes et aux débutants. Cependant, ce n'est pas un dogme, et ça ne devrait pas l'être.
Conséquemment :
Par défaut, visez un seul point de sortie, mais n'en faites pas une doctrine rigide. S'il est justifié d'envisager plusieurs points de sortie, vous pouvez examiner cette avenue.
Envisagez de multiples points de sortie, donc :
Comparez ce cas d'espèce :
| Un seul point de sortie (pencher à droite) | Plusieurs points de sortie (pencher à gauche) |
|---|---|
|
|
... et souvenez-vous que, dans bien des cas, la meilleure solution est de repenser l'interface. Si nous changeons légèrement le mandat de la fonction ci-dessus (voir le commentaire annonçant la fonction), nous pouvons en arriver à :
// retourne une valeur négative si a < b, 0 si a == b, une valeur positive si a > b
int three_way_compare(int a, int b) {
return a - b;
}... qui est nettement mieux!
Quelques liens pour enrichir le propos.
Mon ami Aaron Ballman, dans un tweet privé, m'a indiqué ceci :
« Fun fact: single entry/single exit does *not* mean "only one return statement in the function." It means "single return edge in the call graph".
// This is OKAY
int foo(int i) {
if (i % 2 == 0)
return 0;
return 1;
}
// This is NOT OKAY
int foo(int i) {
if (i % 2 == 0)
return 0;
abort();
}It's not okay because the abort() call has a different return edge (being [[noreturn]]) than the return statement. Source »
