Cette section est touffue du fait (a) qu'on parle d'un langage très riche et très puissant et (b) parce que le sujet m'intéresse particulièrement, il faut bien l'avouer. La liste qui suit n'est pas exhaustive; c'est simplement ce que j'ai eu le temps d'assembler...
| Caractéristique | Depuis... |
|---|---|
Allocateurs munis d'une portée (Scoped Allocators) | |
Annotations [[fallthrough]], [[maybe_unused]] et [[nodiscard]] | |
|
Type any | |
Mot clé auto | C++ 11, mais il s'agit d'une très ancienne caractéristique de C++ |
Les concepts | C++ 20, du moins on l'espère |
Expressions constantes généralisées (mot clé constexpr) | |
Opérateur decltype(expr) | |
Opérateur decltype(auto) | |
« Fonction » declval<T>() | |
Opérations emplace() | |
C++ 98, mais C++ 11 pour les espaces nommés inline et C++ 17 pour les écritures concises d'espaces nommés imbriqués | |
|
C++ 98, mais C++ 11 pour les opérateurs de conversion et C++ 20 pour la version conditionnelle | |
Le type std::function | |
Listes d'initialisation (std::initializer_list) | |
Clause noexcept | |
Les templates | |
Les uplets, ou tuples | |
|
Type variant | |
|
Unification des syntaxes d'appels de fonctions et de méthodes | |
Bibliothèque <chrono> | |
Bibliothèque <random> | |
Bibliothèque <type_traits> |
Pour d'autres sites du même acabit :
J'ai regroupé les considérations quant à l'alignement en mémoire dans ../Sujets/Developpement/Alignement.html
Depuis C++ 11, il est possible de remplacer les alias traditionnellement faits avec typedef par des alias faits avec using. Concrètement, par rapport à typedef, using n'a que des avantages, permettant de faire tout ce que son prédécesseur permettait, de le faire mieux, et de faire plus encore. Quelques exemples suivent.
| Avec using (depuis C++ 11) | Avec typedef (avant C++ 11) |
|---|---|
|
|
|
|
|
|
|
Pas d'équivalent (pas de moyen pour définir partiellement un template) |
|
Pas d'équivalent (on faire un alias comme val_t pour une valeur de It choisie, mais pas un val_t paramétrique sur la base de It) |
Quelques textes :
Voir Gestion-memoire--Liens.html#allocateur pour des détails.
Voir Gestion-memoire--Liens.html#allocateur pour des détails.
Voir ../Sujets/Divers--cplusplus/annotations.html pour des détails.
Les informations ont été regroupées dans ../Sujets/Divers--cplusplus/optional.html
L'Argument-Dependent Lookup (ADL), qu'on nomme parfois aussi le Koenig Lookup (pour Andrew Koening). Un truc à la fois utile et pas simple... Voir ../Sujets/Divers--cplusplus/argument_dependent_lookup.html pour plus d'informations.
Voir ../Sujets/Divers--cplusplus/deduction_types.html#auto pour des détails sur auto
Voir ../Sujets/Divers--cplusplus/deduction_types.html#decltype_expr pour des détails sur decltype(expr)
Voir ../Sujets/Divers--cplusplus/deduction_types.html#decltype_auto pour des détails sur decltype(auto)
Voir ../Sujets/Divers--cplusplus/deduction_types.html#declval pour des détails sur declval<T>()
Des éléments de la nouvelle bibliothèque d'outils de mesure du temps, <chrono> (enfin!) :
Des éléments de la nouvelle bibliothèque stochastique, <random> (un ajout très apprécié au standard du langage!) :
Enfin, des traits sur les types, de manière standard :
Bien qu'en grande partie supplanté par les expressions λ, la fonction std::bind() permet d'associer des paramètres à un appel de fonction, pour par exemple répéter un paramètre, permuter leur position, transformer une fonction binaire (à deux opérandes) en une fonction unaire (à un seul paramètre) avec l'autre paramètre fixé, etc.
Pour un exemple simple :
#include <functional>
#include <iostream>
using namespace std;
void afficher(int a, double b, const char *c) {
cout << a << ' ' << b v< ' ' << c << endl;
}
int main() {
using namespace std::placeholders;
afficher(2, 3.5, "J'aime mon prof!");
auto rev = bind(afficher, _3, _2, _1);
rev("Yo", 3.5, 3); // les paramètres sont passés en ordre inverse
auto f = bind(afficher, 3, 3.1459f, "J'aime encore mon prof!!!");
f(); // les trois paramètres sont fixés
auto g = bind(afficher, _1, _1, "J'aime encore mon prof!!!");
g(7); // afficher(7, 7, "J'aime encore mon prof!!!");
}Le type std::byte vise à remplacer, éventuellement, le recours à char en tant que représentation d'un byte, pour redonner à char son rôle de représentation d'un caractère. Notez que std::byte n'est pas un type arithmétique (bien qu'il admette des opérations bit à bit); son rôle est de modéliser un espace d'entreposage.
Notez que, sur le plan historique, de nombreux types nommés byte existent dans des en-têtes de plateformes (par exemple, un alias byte est défini dans <windows.h>), alors il est préférable d'éviter using namespace std; si vous incluez des en-têtes de plateformes, pour éviter les conflits de noms avec ce type.
Les informations sur les concepts ont été regroupées sur ../Sujets/Divers--cplusplus/Concept-de-concept.html
Expressions constantes généralisées, ou constexpr : ../Sujets/Divers--cplusplus/constexpr.html
Il est possible depuis C++ 11 de faire en sorte qu'un constructeur délègue son travail à un autre constructeur.
Il est possible depuis longtemps d'exposer, dans une classe dérivée, des services cachés d'un parent, à l'aide du mot-clé using. Depuis C++ 11, ce mécanisme est aussi applicable aux constructeurs.
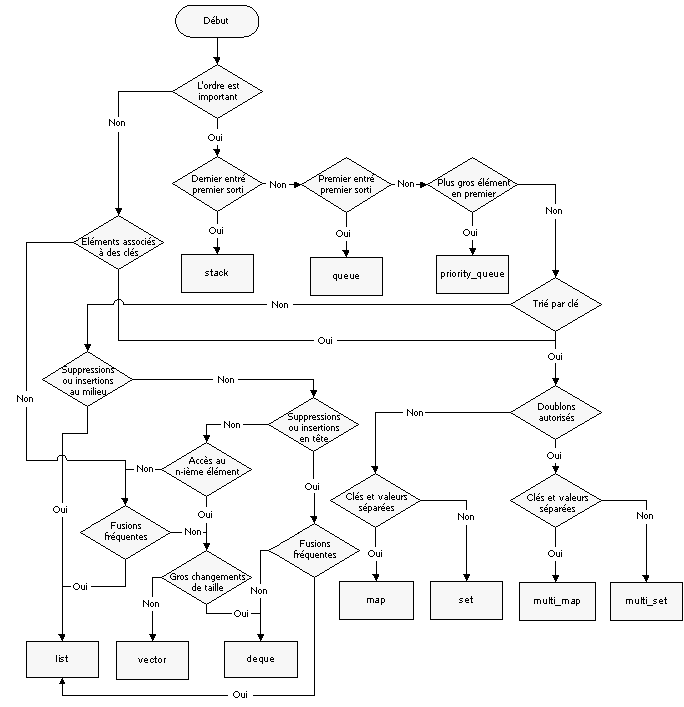
Les conteneurs et les itérateurs sont, avec les algorithmes standards, au coeur des pratiques contemporaines de programmation en C++.
J'ai relocalisé ce que j'avais à ce sujet sur un (court) article que vous trouverez sur ../Sujets/TrucsScouts/declaration_a_priori.html
Opérations emplace(). Raffinement des traditionnels insert(), push_front(), push_back() etc. des conteneurs standards de C++. L'idée est de construire les éléments à même le conteneur, plutôt que de construire une temporaire et de la copier dans le conteneur par la suite :
À propos des énumérations fortes, un important raffinement en comparaison avec les énumérations « classiques » :
Certains disent aussi espaces de noms :
| Avant C++ 17 | Depuis C++ 17 |
|---|---|
|
|
Une question qui revient souvent, en lien avec les espaces nommés, est le recours à un espace nommé anonyme, par exemple :
namespace {
int glob = 3; // variable globale, ::glob de son vrai nom
}Techniquement, les éléments d'un espace nommé anonyme ne sont pas visibles à l'édition des liens. Ceci remplace en quelque sorte la qualification static apposée traditionnellement sur les fonctions et les variables qui devaient être locales à un seul module objet dans un programme C.
L'avantage des espaces nommés anonymes sur la qualification static est qu'ils permettent aussi de cacher des types à l'éditeur de liens, alors que static ne s'applique qu'aux variables et aux fonctions.
Les informations sur les concepts ont été regroupées sur ../Sujets/Divers--cplusplus/explicit.html
À propos des expressions régulières, enfin supportées de manière standard depuis C++ 11 :
Les informations sur les concepts ont été regroupées sur ../Sujets/Divers--cplusplus/final.html
À propos des flux :
À propos des foncteurs (aussi nommés Function Objects) : ../Sujets/Divers--cplusplus/foncteurs.html
À propos des fonctions inline : ../Sujets/Divers--cplusplus/inline.html#fonction
À propos des variables inline : ../Sujets/Divers--cplusplus/inline.html#variable
Depuis C++ 11, il est possible de remplacer une répétitive comme celle-ci :
for(vector<T>::iterator it = begin(v); it != end(v); ++it)
f(*it);... par une répétitive comme celle-là :
for(T &elem : v)
f(elem);... ou encore, de manière plus générale, comme celle-là :
for(auto &elem : v)
f(elem);Il est possible de manipuler ainsi les éléments de tout conteneur pour lequel les fonctions globales std::begin() et std::end() s'appliquent. Il est possible de manipuler les éléments :
Par copie : |
|
Par référence : |
|
Par référence-vers-const : |
|
Notez que le paramètre de la boucle représentant le conteneur sur les éléments duquel on itérera ne sera évalué qu'une seule fois. Ainsi, le programme suivant :
#include <iostream>
#include <vector>
using namespace std;
vector<int> f() {
cout << "Appel de f()" << endl;
vector<int> v { 1,2,3,4,5 };
v.push_back(6);
return v;
}
int main() {
for(auto i : f())
cout << i << endl;
}... offrira la sortie suivante sur tous les compilateurs contemporains :
Appel de f()
1
2
3
4
5
6Vous conviendrez que la nouvelle forme est plus concise que celle qui l'a précédée. Les boucles for sur des intervalles simplifient certaines pratiques usitées :
Le type std::function qui joue en C++ le rôle des délégués en C#. Pour une introduction : ../Sujets/TrucsScouts/intro_std_function.html
Des tables de hashage :
L'héritage avec C++ :
À partir de C++ 17, il devient possible de définir des variables à même un if ou un switch, de manière à ce que la portée de telles variables soit locale à la structure de contrôle. Par exemple :
| Avant C++ 17 | Depuis C++ 17 |
|---|---|
|
|
|
|
Ceci est particulièrement sympathique en combinaison avec les Structured Bindings :
| Avant C++ 17 | Depuis C++ 17 | Depuis C++ 17 avec Structured Bindings |
|---|---|---|
|
|
|
À ce sujet :
Les informations ont été regoupées dans ../Sujets/Divers--cplusplus/if_constexpr.html
Les informations ont été regroupées dans ../Sujets/Divers--cplusplus/NSDMI.html
Les informations ont été regoupées dans ../Sujets/AuSecours/initialisation-uniforme.html
L'internationalisation (on écrit aussi i18n, car il y a 18 lettres entre le « i » et le « n ») :
Les λ, qui allègent tellement les tâches courantes... Voir ../Sujets/Divers--cplusplus/Lambda-expressions.html pour des détails
J'ai groupé l'information à ce sujet dans ../Sujets/Divers--cplusplus/initializer_lists.html
Ils est maintenant possible d'exprimer des littéraux binaires en C++. Par exemple, les expressions ci-dessous décrivent le même nombre :
| Décimal | Décimal avec séparateurs | Octal | Hexadécimal | Binaire |
|---|---|---|---|---|
|
|
|
|
|
J'ai regroupé dans ../Sujets/Divers--cplusplus/litteraux_maison.html l'information sur les littéraux maison, par lesquels il devient possible d'enrichir la gamme des littéraux du langage.
Les littéraux texte bruts, très utiles à l'ère Internet, entre autres pour manipuler du texte balisé et des expressions régulières :
| À titre d'exemple, ceci... | ...est équivalent à cela |
|---|---|
|
|
Ces deux écritures décrivent le même const char*. On peut préférer l'un ou l'autre, mais les deux options existent.
Considérations de gestion de mémoire avec C++ :
La métaprogrammation est un sujet chaud dans ce langage :
Il est possible depuis C++ 11 d'appliquer les qualification & et && à des méthodes, en plus des qualifications const et volatile.
La clause noexcept : ../Sujets/Developpement/Exceptions.html#noexcept
Notez qu'il est très facile d'abuser de la surcharge d'opérateurs, etr certains des liens qui suivent donnent des trucs qui pourraient mener à du code plus difficile à utiliser ou brisant le principe de moindre surprise. Agissez avec discrimination, et souvenez-vous que le code est lu plus souvent qu'il est écrit!
Les opérateurs et leur surcharge :
Les informations ont été regroupées dans ../Sujets/Divers--cplusplus/explicit.html#operateur_conversion
Les informations ont été regroupées dans ../Sujets/Divers--cplusplus/optional.html
Que veut-on dire par « mot-clé contextuel »? Voici un exemple qui pousse l'idée vers l'absurde (emprunté à Adi Shavit dans https://twitter.com/AdiShavit/status/913758314009415681) :
Le mot clé contextuel (et optionnel) override permet d'expliciter l'intention, dans une classe dérivée, de spécialiser une méthode polymorphique d'une classe parent.
J'ai groupé les informations portant sur les pointeurs intelligents dans ../Sujets/AuSecours/pourquoi_pointeurs_intelligents.html
Vous trouverez d'autres liens sur ce sujet dans la section commune aux langages C et C++.
Le préprocesseur est une chose à éviter en C++, mais parfois... :
Les références sur des rvalue (rvalue references) :
Ils est maintenant possible d'exprimer des littéraux binaires en C++. Ceci peut améliorer la lisibilité, du moins si on l'utilise judicieusement. La séparateur utilisé est l'apostrophe. Ainsi, les écritures suivantes sont équivalentes :
| Décimal | Décimal avec séparateurs | Octal | Octal avec séparateurs | Hexadécimal | Hexadécimal avec séparateurs | Binaire | Binaire avec séparateurs |
|---|---|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
À propos de la standardisation de l'initialisation, qui rapproche le langage de l'un de ses objectifs, soit celui de traiter tous les types sur un même pied :
Avec C++ 17, il devient possible de déconstruire un struct ou un tuple retourné par une fonction en ses éléments constitutifs, de manière à faciliter l'accès à ces membres dans le contexte du code client. Par exemple :
| Avant C++ 17 | À partir de C++ 17 |
|---|---|
|
|
À ce sujet :
Lors de la rencontre du WG21 à Kona en 2017, nous avons discuté d'une dichotomie entre le texte du Core Language, qui utilisait le terme Decomposition Declarations pour l'expression en soi et le terme Structured Bindings pour les variables découlant de cette décomposition, car il y avait une volonté d'utiliser strictement Structured Bindings dans le texte pour réduire la confusion des programmeuses et des programmeurs lorsque celles ou ceux-ci verront apparaître un message d'erreur à la compilation.
Après quelques débats, mettant entre autres en valeur l'importance de distinguer l'expression et son résultat, nous avons convenu d'utiliser Structured Bindings et Structured Binding Declarations. Ces termes devraient être ceux que vous rencontrerez en pratique, mais sachez que Decomposition Declarations a été utilisé pendant un certain temps pour ce qui sera désormais nommé Structured Binding Declarations.
C++ permet de distinguer deux fonctions sur la base d'un certain nombre de critères. En effet, dans ce langage, deux fonctions sont différentes si :
Cette caractéristique du langage complique quelque peu l'interopérabilité au niveau du code machine généré : les noms dans le code machine sont typiquement différents du nom dans le code source; en ce sens, interopérer avec du code écrit en langage C, où il n'est pas légal d'avoir deux fonctions distinctes du même nom, est plus simple. Il est toutefois possible de faire de petits miracles à l'aide de cette mécanique. Notez que plusieurs utilisent enable_if pour contrôler la sélection de fonctions par le compilateur lorsque celui-ci cherche à déterminer laquelle des fonctions serait la plus à propos pour un certain appel.
Il est possible depuis C++ 11 d'écrire une fonction dont le type suit la signature plutôt que de la précéder... Et c'est parfois très utile!
Il est possible depuis C++ 11 de définir des templates avec spécialisations partielles, ce qui permet d'alléger énormément certaines écritures lourdes (en particulier celles en lien avec les traits) :
Les templates variadiques permettent de suppléer un nombre arbitrairement grand de paramètres à une fonction :
Le transtypage, aussi nommé conversions explicites de type ou encore – en anglais – les Type Casts, ou simplement Casts :
Les tuples, ou uplets en français :
Questions de types, en particulier les types primitifs du langage :
Depuis C++ 14, il est possible de définir des variables génériques (en plus des types et des fonctions génériques, bien connues des programmeuses et des programmeurs C++ de manière générale). Ceci permet d'exprimer du code générique tel que :
template <class T>
constexpr const T PI = T(3.1415926535897932384626433832795);
template <class T>
T circonference_cercle(T rayon) {
return T(2) * PI<T> * rayon;
}Textes d'autres sources :
À propos des mots clés contextuels
Depuis C++ 11, certains mots clés de C++ sont contextuels, au sens où ils ne sont des mots clés que lorsque placés à certains endroits dans un programme. Ceci est dû au risque élevé que ces mots apparaissent ailleurs dans du code existant. C++ est décrit par un standard ISO et qu'il ne s'agit pas d'un produit appartenant à une entreprise ou l'autre, briser le code existant lors d'une mise à jour du standard est une préoccupation importante du comité de standardisation.
Les mots clés contextuels incluent override et final.
Pour en savoir plus :
Les informations ont été regroupées dans ../Sujets/Divers--cplusplus/optional.html
Chacun à sa manière, en 2014, Bjarne Stroustrup et Herb Sutter ont proposé d'unifier (avec nuances de part et d'autre) les syntaxes obj.f(args) et f(obj,args), ce qui refléterait la pratique existante pour des cas comme begin(conteneur) et conteneur.begin().

{kind=link}