
Les équations sur ctte page sont affichées à l'aide de MathJax.
Il y a des sujets qui, pour d'étranges raisons, font plus peur que d'autres. Les pointeurs, par exemple, ou encore le polymorphisme, qui sont des exemples classiques de concepts essentiels en informatique et qui semblent entourés d'une aura de crainte, crainte somme toute peu justifiée.
Le présent document s'intéressera à l'un de ces sujets à haute teneur en crainte : la récursivité.
Imaginons que nous ayons le mandat suivant :
Écrire une fonction somme_un_a(n) qui prenne en paramètre un entier et qui retourne la somme de à inclusivement.
Nous adopterons la convention que la fonction doive retourner si pour que le tout soit simple, et nous présumerons qu'aucun débordement ne se produira en cours de route, toujours dans l'optique de garder le propos aussi simple que possible.
Notez que j'utilise pour décrire l'intervalle discret fermé allant inclusivement de à . L'écriture est pour moi ce qu'on appelle un intervalle à demi-ouvert, où est inclus et est exclu.
La plupart des informaticiennes et des informaticiens auront sans doute le réflexe de résoudre ce problème à l'aide d'une répétitive, ce qui est une stratégie très raisonnable :
long somme_un_a(int n) {
long cumul = {};
for (int i = 1; i <= n; i++)
cumul += i;
return cumul;
}long somme_un_a(int n) {
long cumul = {};
int i = 1;
while (i <= n) {
cumul += i;
i++;
}
return cumul;
}On pourrait aussi définir cette fonction de la manière suivante :
long somme_un_a(int n) {
if (n <= 0)
return 0L;
else
return n + somme_un_a(n-1);
}Les versions avec répétitives sont plus efficaces dans ce cas-ci, mais la version où la fonction résout le problème en se rappelant elle-même a le mérite d'être très simple :
La stratégie d'ensemble d'une fonction récursive y est claire :
Celles ou ceux parmi vous qui sont familières ou familiers avec les techniques de preuve mathématique reconnaîtront peut-être dans la récursivité des similitudes avec la technique de preuve par induction.
Les fonctions récursives sont l'enfant chéri des mathématicien(ne)s; il est fréquent que des structures mathématiques soient définies de manière récursive, ce qui est compréhensible: règle générale, une stratégie récursive s'exprime de manière simple, élégante et compacte.
Un cas célèbre est la définition des entiers naturels, donnée par Giuseppe Peano, qui décrit les entiers à partir d'un entier de base (zéro) et de l'opération successeur (écrite succ(), à droite). Dans ce modèle, donc, écrire est un raccourci pour écrire successeur de (successeur de (0))). L'un des points où l'informatique se distingue fréquemment de la mathématique est le souci de trouver non seulement une solution à un problème, mais aussi une solution efficace. En effet, si exprimer la somme de de manière récursive est élégant et compact, c'est aussi une stratégie très inefficace (ne généralisons toutefois pas le cas à toutes les stratégies récursives: il y a des cas où une approche récursive constitue véritablement la stratégie à adopter; le truc est de choisir ses combats et de choisir les armes les plus efficaces pour faire face à chaque adversaire). |
|
On peut tracer rapidement ce que cette stratégie donnerait pour lors de l'invocation initiale de somme_un_a() :
somme_un_a(5) == 5 + somme_un_a(4)
== 5 + (4 + somme_un_a(3))
== 5 + (4 + (3 + somme_un_a(2)))
== 5 + (4 + (3 + (2 + somme_un_a(1))))
== 5 + (4 + (3 + (2 + (1 + somme_un_a(0)))))
== 5 + (4 + (3 + (2 + (1 + (0)))))
== 5 + (4 + (3 + (2 + (1))))
== 5 + (4 + (3 + (3)))
== 5 + (4 + (6))
== 5 + (10)
== 15Certaines outils, en particulier ceux pensés pour les langages fonctionnels, tendent à optimiser les expressions récursives quand la récursivité apparaît à la toute fin, ce qu'on appelle de la Tail Recursion. Pour une explication de cette mécanique, voir http://rodrigosasaki.com/2012/11/24/tail-recursion/.
Remarquez que la solution du problème résulte d'un cumul de données. La stratégie récursive repousse à la toute fin de la récursion la tâche de mettre ensemble les petits morceaux de calculs trouvés en chemin.
Cela a pour effet qu'une fonction récursive requiert, en général, des ressources cumulatives pour en arriver à un résultat, quand bien même ce ne serait que pour gérer les appels à la fonction récursive qui s'empilent jusqu'à obtention d'un résultat: somme_un_a(5) ne peut se compléter sans avoir obtenu le résultat de somme_un_a(4), qui dépend du résultat de somme_un_a(3), et ainsi de suite, ce qui fait en sorte que somme_un_a(n) entraînera, au pire moment, (en fait, , mais cela importe peu) appels empilés à somme_un_a().
Chaque appel entraîne l'utilisation d'espace pour les états intermédiaires (valeur de retour, variables locales, etc.) ce qui peut devenir très, très coûteux :
Dans le schéma qui précède, en forme de pyramide, le pic de la pyramide représente le moment où on a atteint le coût maximal en ressources pour un appel original à somme_un_a(5). On imagine bien le coût de somme_un_a(10000), surtout en comparaison avec une stratégie itérative qui ne ferait que itérations dans une répétitive et qui, en ne se rappelant pas, ne nécessiterait qu'un seul appel à la fonction somme_un_a().
On prétend (est-ce une légende urbaine?) que Carl Friedrich Gauss, un très grand mathématicien (certains l'ont qualifié de Prince des mathématiciens), était un élève turbulent à la petite école, et que son maître lui avait accolé le problème de calculer la somme des entiers situés inclusivement entre et , pensant ainsi le tenir occupé.
Selon la légende, il aurait très rapidement répondu correctement (), ayant remarqué que, si on aligne les entiers à additionner côte à côte, on obtient :
qu'on peut grouper par paires comme suit :
de manière à ce que la valeur dans chaque parenthèse soit la même (), et qu'il y ait (, donc ) parenthèses.
Le reste est affaire de multiplication élémentaire, qui se généralise simplement :
long somme_un_a(int n) {
long cumul = {};
if (n > 0)
if (n % 2 == 0) // n pair
cumul = (1 + n) * (n / 2);
else
cumul = n + (1 + (n - 1)) * ((n-1) / 2);
return cumul;
}ce qui est, en soi, une définition récursive :
long somme_un_a(int n) {
if (n <= 0)
return 0L;
else if (n % 2 == 0) // n pair
return (1 + n) * (n / 2);
else
return n + somme_un_a(n-1);
}mais seulement par la bande. En fait, cette stratégie demande un temps constant à appliquer, peu importe la valeur originale de , alors que les stratégies itératives et récursive proposées plus haut demandent un temps linéaire (le temps requis pour traiter le problème croît de manière proportionnelle à la valeur de ). Ici, une analyse mathématique – même simple – comme celle faite par Gauss représente un gain considérable de qualité.
Imaginons que nous ayons le mandat suivant :
Écrire une fonction puissance(base,exp) qui prenne en paramètre deux entiers, base et exp. Pour simplifier le propos, nous présumerons base > 0, exp >= 0 et nous présumerons que baseexp ne provoque aucun débordement de capacité (pour voir comment on pourrait garantir le respect des contraintes base > 0 et exp >= 0 à coût presque zéro, voir cet encadré).
Ici encore. une solution répétitive est très accessible – il s'agit même d'un problème fréquemment servi à des étudiant(e)s inscrit(e)s dans un cours de base de programmation :
long puissance(int base, int exp) {
long cumul = 1L;
for (int i = 0; i < exp; ++i)
cumul *= base;
return cumul;
}long puissance(int base, int exp) {
long cumul = 1L;
int cpt = 0;
while (cpt < exp) {
cumul *= base;
++cpt;
}
return cumul;
}On pourrait aussi définir cette fonction de la manière suivante, qui est simple et relativement inefficace, à l'image de la version récursive de somme_un_a() plus haut.
long puissance(int base, int exp) {
if (!exp)
return 1L;
else
return base * puissance(base, exp - 1);
}Pour se le prouver, traçons l'appel puissance(2,5) :
puissance(2,5) == 5 * puissance(2,4)
== 5 * (4 * puissance(2,3))
== 5 * (4 * (3 * puissance(2,2)))
== 5 * (4 * (3 * (2 * puissance(2,1))))
== 5 * (4 * (3 * (2 * (1 * puissance(2,0)))))
== 5 * (4 * (3 * (2 * (1 * 1))))
== 5 * (4 * (3 * (2 * (1))))
== 5 * (4 * (3 * (2)))
== 5 * (4 * (6))
== 5 * (24)
== 120mais ce n'est pas la seule manière possible de procéder. Une analyse plus poussée du problème révèle des trucs amusants : en effet, il se trouve que si exp est pair, alors exp peut s'écrire sous la forme avec entier. On sait alors que :
baseexp == base2*n
== basen+n
== basen*basen
==(basen)2On voit donc poindre à l'horizon une forme de récursivité beaucoup plus intéressante: lorsque exp est pair, on peut évaluer baseexp en calculant baseexp/2 et en multipliant cette valeur par elle-même, diminuant ainsi de moitié la complexité du problème!
Évidemment, si exp est impair, on aura recours à la version plus simple qui consiste à calculer base*puissance(base,exp-1).
Cette version plus efficace pourrait se présenter comme suit :
bool est_pair(int n) {
return n % 2 == 0;
}
long puissance(int base, int exp) {
if (exp == 0)
return 1L;
else if (est_pair(exp)) {
auto temp = puissance(base,exp/2);
return temp * temp;
} else
return base * puissance(base, exp - 1);
}Remarque : dans la fonction puissance(), l'ordre dans lequel sont évaluées les conditions est important.
En effet, est pair; si nous avions décidé de vérifier si exp est pair avant de vérifier si exp==0, alors nous aurions eu un cas de récursivité à l'infini sous les bras, puisque si exp==0, alors
puissance(base,exp/2) == puissance(base,0)Dans une fonction récursive, il faut donc évaluer avec soin à la fois la condition qui pemettra à la récursivité de s'arrêter, et l'ordre dans lequel on examinera les cas qui nous permettront de décider de la marche à suivre.
Pour visualiser l'impact de cette manoeuvre, traçons l'appel puissance(2,10). Nous utiliserons n^2 pour signaler l'élévation au carré de n, en présumant qu'il s'agit d'une opération primitive puisque, dans la fonction, nous utilisons une variable temporaire qu'on multiplie par elle-même pour réaliser cette opération (donc on ne procède par récusivement) :
puissance(2,10) == puissance(2,5)^2
== (2 * (puissance(2,4))^2
== (2 * puissance(2,2)^2)^2
== (2 * (puissance(2,1)^2)^2)^2
== (2 * ((2*puissance(2,0))^2)^2)^2
== (2 * ((2*1)^2)^2)^2
== (2 * (2^2)^2)^2
== (2 * 4^2)^2
== (2 * 16)^2
== (32)^2
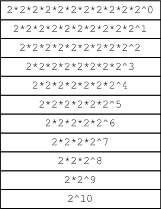
== 1024Il peut être intéressant de comparer la stratégie récursive naïve avec celle-ci pour voir la différence de complexité entre les deux approches. Visuellement, les pire cas (en terme de récursivité) des deux approches se présentent, pour puissance(2,10), comme suit.
La notation 2^n a été préférée à la notation puissance(2,n) dans ces schémas pour économiser de l'espace, mais n'oubliez pas que, dans la stratégie de droite, l'opération n^2 est une opération primitive (se fait sans récursivité) dans tous les cas sauf un (en gras et en italiques) qui constitue un légitime appel à puissance(2,2).
L'algorithme naïf est de complexité linéaire: le nombre d'appels récursifs à puissance(base,exp) croît linéairement avec la valeur de exp.
L'algorithme raffiné est de complexité logarithmique: le nombre d'appels récursifs à puissance(base,exp) croît de manière se rapprochant de . La raison pour cela est que la taille du problème se divise par deux pour chaque exp pair, donc en moyenne à chaque deux appels.
Pour donner une image comparative de la complexité de ces deux algorithmes, indiquons que pour exp==1000, on aura autour de 1000 appels récursifs dans un cas et aux alentours de 15 dans l'autre (exp vaudra 1000, 500, 250, 125, 124, 62, 31, 30, 15, 14, 7, 6, 3, 2, 1 et 0, ce qui donne précisément 16 appels). Si l'algorithme était de complexité strictement logarithmique, donc si on ne devait pas traiter le cas où exp est impair différemment, alors on n'aurait que 10 appels. C'est une différence considérable!
| puissance(2,10), pire cas | |
|---|---|
| Algorithme naïf | Algorithme plus raffiné |
|

|
Ne nous y méprenons pas: si la différence est visible avec exp==10, elle ira en s'accroissant alors que exp croîtra. Notez que cette assertion doit être vérifiée (il y a des algorithmes efficaces sur de petits problèmes mais beaucoup moins efficaces sur de grands problèmes), mais est véridique dans ce cas-ci.
C'est un indice important dans le choix d'un algorithme: plus la taille du problème est grande et plus l'écart se creuse entre un bon algorithme et un moins bon.
On fait souvent appel à l'informatique pour résoudre des problèmes que des humains ne pourraient pas raisonnablement résoudre sans outils. Des problèmes demandant beaucoup de calculs, par exemple; le tri de vastes quantités de données; des problèmes où le nombre d'opérations est tel que la force brute devient nécessaire; etc. Les gains apportés par l'emploi de bons algorithmes sont, dans la majorité des cas, beaucoup plus importants que ceux apportés par l'usage d'un ordinateur plus puissant.
Clairement, dans ce cas-ci, la récursivité, bien appliquée, nous permet de concevoir un algorithme beaucoup plus efficace que l'algorithme récursif naïf ou que l'algorithme itératif (avec une boucle), dont la complexité est linéaire (le nombre d'itérations requis pour calculer puissance(base,exp) suit de manière linéaire la valeur de exp).
Visiblement, la récursivité n'est pas la solution à tous les maux, mais peut être un outil conceptuel de grande valeur.
Comment pourrait-on écrire la fonction puissance(base,exp) de manière à ce que :
Une manière simple d'y arriver est d'appliquer une façade de validation : la fonction ayant la signature attendue (ici : puissance(base,exp)) est exposée (dans un fichier d'en-tête) est sera appelée par le sous-programme utilisateur. Notez que vous trouverez des informations sur les templates dans cet article.
#include <string>
#include <sstream>
//
// Ce qui suit est discutable, mais suffira pour cet article
//
template <class T>
struct ParametreInvalide {
std::string nom;
T valeur;
std::string message() const {
return "Paramètre invalide: (" + nom + "): " + to_string(valeur);
}
ParametreInvalide(const std::string &nom, const T &val) : nom{ nom }, valeur{ val } {
}
};
//
// Prototype de la fonction
//
long puissance(int base, int exp);Toutefois, cette fonction n'est qu'une façade, qui procède à une validation unique des paramètres. Pour son traitement, elle fait appel à une autre fonction qui, elle, n'est pas exposée (qui est cachée dans un .cpp), et c'est cette fonction cachée qui, confiante que ses paramètres respectent les invariants attendus, procédera pleine valeur et récursivement sans les valider.
La même technique s'appliquerait dans une stratégie OO en utilisant une méthode publique comme façade de validation et une méthode privée pour la version rapide mais sans validation pour le calcul brut.
Dans notre exemple, puissance(base,exp) est la façade qui procède à la validation du respect des invariants par les paramètres base et exp, et ::puissance_impl(base,exp) fait le réel travail pour calculer l'élévation de base à la puissance exp.
Procédant ainsi, ::puissance_impl(base,exp) peut déployer au maximum sa puissance de calcul et puissance(base,exp) offre aux sous-programmes utilisateurs la sécurité à laquelle ils sont en droit de s'attendre. Plus exp est grand et moins la façade sera coûteuse.
// inclure le fichier d'en-tête...
namespace {
//
// est_pair(n), simple et efficace
//
bool est_pair(int n) {
return n % 2 == 0;
}
//
// Fonction brute, usage interne seulement, paramètres
// présumés préalablement validés
//
long puissance_impl(int base, int exp) {
if (exp == 0)
return 1L;
else if(est_pair(exp)) {
auto temp = puissance_impl(base,exp/2);
return temp * temp;
} else
return base * puissance_impl(base, exp - 1);
}
}
//
// Définition de la fonction façade
//
long puissance(int base, int exp) {
if (base <= 0)
throw ParametreInvalide<int>("Base", base);
else if (exp < 0)
throw ParametreInvalide<int>("Exp", exp);
return ::puissance_impl(base, exp);
}Une variante plus concise de la stratégie précédente est d'avoir recours à une expression λ interne à la fonction servant de façade. Le code suit :
// inclure les fichiers d'en-tête...
bool est_pair(int n) {
return n % 2 == 0;
}
//
// Définition de la fonction façade
//
long puissance(int base, int exp) {
if (base <= 0)
throw ParametreInvalide<int>("Base", base);
else if (exp < 0)
throw ParametreInvalide<int>("Exp", exp);
function<long(int,int)> impl = [&](int base, int exp) -> long {
if (exp == 0)
return 1L;
else if(est_pair(exp)) {
auto temp = puissance_impl(base,exp/2);
return temp * temp;
} else
return base * puissance_impl(base, exp - 1);
};
return impl(base, exp);
}Ici, l'expression λ est logée dans une std::function de manière à être nommée, puis ce nom est capturé par référence dans la λ pour y être utilisé comme une opération récursive. Cette opération est efficace du fait que ses paramètres sont nécessairement valides.
Il existe des cas où la stratégie récursive brute est la plus élégante mais entraîne des coûts considérables. L'un des cas les plus étudiés en ce sens est l'algorithme de Fibonacci, qui décrit entre autres la croissance de certaines plantes et de certaines populations animales.
Cette fonction prend un seul paramètre, un entier naturel , et sera nommée fib(n) ci-après.
Son expression naturelle en mathématiques est récursive :
L'écriture récursive de fib(n) va de soi à partir de la définition (on pourrait la garnir d'une façade pour assurer , mais nous omettrons ce détail ici pour garder le tout simple) :
long fib(int n) {
if (n < 2) // ou if (n == 0 || n == 1)
return 1L;
else
return fib(n-1) + fib(n-2);
}Cette version fonctionne bien, d'ailleurs, mais est terriblement lente pour de grandes valeurs de n. Pour comprendre le problème, traçons l'appel à fib(7) :
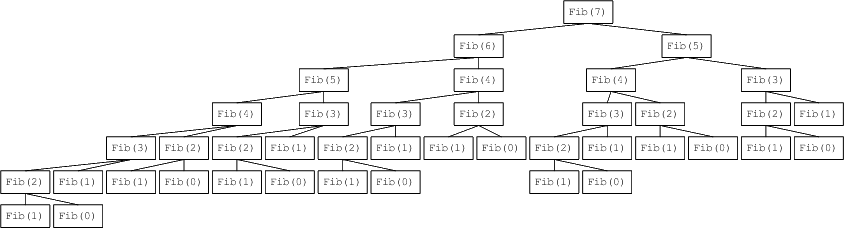
Ce qu'on doit remarquer ici pourcomprendre le problème, c'est à quel point les calculs redondants y sont nombreux. Par exemple, fib(3) y est calculé pas moins de cinq fois, et implique à lui seul le calcul de fib(2), de fib(1) (deux fois!) et de fib(0). On a peine à imaginer la complexité d'un calcul comme fib(25) fait de manière aussi naïve!
Idéalement, on ne calculerait chaque valeur de fib(n) qu'une seule fois, et on réutiliserait cette valeur chaque fois qu'on en aurait besoin, car chaque calcul de fib(n) pour une valeur de n donnée résulte en une arborescence de calculs. Prenons par exemple fib(5), du côté droit et du côté gauche de l'arborescence ci-dessus: si on avait retenu sa valeur la première fois que celle-ci aurait dû être calculée, alors l'un des deux arbres aurait pu être omis en totalité!
Une version itérative de fib(n) tenant compte de cette réalisation utiliserait un grand tableau. Ici, nous utiliserons new pour le créer et delete pour le détruire, mais si le calcul rapide de fib(n) était important dans un programme, alors on privilégierait l'emploi d'un gros tableau (au moins autant d'éléments que le plus gros n susceptible d'être passé en paramètre à fib()) alloué à l'avance, car l'allocation dynamique de mémoire est une opération coûteuse.
Remarque : cette version de fib(n) est moins élégante et plus... technique, disons, que la version récursive. On doit y manipuler un tableau, jongler avec des index, procéder à l'aide d'une répétitive, et ainsi de suite.
Cela dit, sa complexité est linéaire (en gros : calculer fib(n) demande aux alentours de opérations), alors que la version récursive de fib(n) a une complexité absolument démentielle, et devient rapidement hors de contrôle – inutilisable, à toutes fins pratiques – alors que croît.
Pour les intéressé(e)s, il existe une manière d'obtenir fib(n) en temps constant, mais cette stratégie exploite des opérations sur des réels (utilisant le nombre d'or, un irrationnel bien connu) et peut donc pêcher par manque de précision.
| Fibonacci (itératif) |
|---|
|
| Fibonacci (itératif, avec un std::vector – mieux!) |
|
Notez que pour la version itérative de fib(n) pour une valeur de n donnée, le recours à un conteneur est abusif; conserver les deux plus récentes valeurs de fib() suffit en tout temps. L'allocation dynamique de ressources qu'implique le recours à un tableau ou à un vecteur tendra, en pratique, à prendre beaucoup plus de temps que les deux affectations supplémentaires par itération dans le code ci-dessous :
| Fibonacci (itératif, moins coûteux) |
|---|
|
Définir fib(n) de manière récursive est clair et élégant. Implémenter fib(n) de manière récursive, par contre, n'est pas une démarche pragmatique.
struct Noeud {
int valeur;
Noeud *succ {};
public:
Noeud(int valeur) : valeur{valeur} {
}
Noeud(const Noeud &n) : val{ n.valeur() } {
}
};
class Liste {
Noeud *tete {};
public:
Liste()= default;
void ajouter(int n) {
auto p = new Noeud{ n };
if (!empty())
p->succ = tete;
tete = p;
}
bool empty() const {
return !tete;
}
int size() const;
void afficher_elements() const;
void afficher_elements_inverse() const;
void clear() {
for (auto p = tete; p; ) {
auto q = p->succ;
delete p;
p = q;
}
tete = {};
}
// etc.
};Imaginons qu'on ait une liste simplement chaînée définie comme suit (à droite). Il est évidemment possible de faire beaucoup mieux.
Chaque instance de Noeud possède une valeur (constante) et connaît son successeur (un autre Noeud, ou nullptr si elle n'a pas de successeur).
Une liste a une tête (un Noeud). Elle est considérée vide si sa tête est un pointeur nul. On peut ajouter à la liste (l'ajout se fait en début de liste, pour fins de simplicité).
Trois des opérations qui sont déclarées dans cette classe Liste ne sont pas encore définies. Il s'agit de :
Nous présenterons des implémentations possibles pour ces trois méthodes, et nous examinerons l'utilité (ou non) d'une stratégie récursive dans chaque cas.
En l'absence d'un compteur toujours à jour pour le nombre d'éléments dans la liste, la manière la plus simple de calculer ce nombre d'éléments est de parcourir cette liste à partir de sa tête jusqu'à ce qu'on atteigne un noeud qui n'ait pas de successeur et de les compter, tout simplement. Dans la version récursive, Liste::size() const sert de façade à une fonction plus générique.
| Version itérative | Version récursive | Version récursive (concise) |
|---|---|---|
|
|
|
Visiblement, les deux versions sont aussi complexes l'une que l'autre. Dans un tel cas, on privilégiera presque toujours l'approche itérative, qui nécessite un nombre constant (un seul!) d'appels de méthode, à l'approche récursive, qui exige un nombre d'appels de méthodes qui croît de manière linéaire avec le nombre d'éléments dans la liste.
Encore une fois, il faudra parcourir la liste élément par élément pour afficher la valeur de chacun. Dans la version récursive, Liste::afficher_elements() const sert de façade à une fonction plus générique.
| Version itérative | Version récursive |
|---|---|
|
|
Encore une fois, les deux versions sont aussi complexes l'une que l'autre, et on privilégiera l'approche itérative.
Ici, par contre, une version itérative serait relativement complexe à implémenter :
La stratégie récursive, elle, est toute simple et sa complexité est linéaire. Ici, Liste::afficher_elements_inverse() const sert de façade à une fonction plus générique
| Version itérative (a) | Version récursive |
|---|---|
|
|
| Version itérative (b) | |
|
Clairement ici, la complexité et la clarté de la version récursive constituent des atouts importants sur leur contrepartie itérative. Dans ce cas, la version récursive serait celle qu'on souhaiterait implémenter.
Risques d'abus
Un bref bémol s'impose quant à la taille de la pile d'exécution d'un programme (voir ce document pour en savoir plus sur le sujet de la pile d'exécution).
En effet, chaque thread d'un programme se fait attribuer par le système d'exploitation un espace pour gérer la dynamique de ses appels et l'espace requis pour entreposer les variables locales lors d'appels à ses sous-programmes. Cet espace se nomme la pile d'exécution du thread, et n'est pas infini en taille. On peut fixer la taille de la pile d'un thread donné par des mécanismes propres à chaque compilateur et à chaque système d'exploitation, mais il y a toujours un risque qu'un thread sollicite tellement sa pile d'exécution que celle-ci déborde. Un débordement de pile est une erreur grave, et provoque systématiquement l'échec à l'exécution d'un programme.
évidemment, la récursivité reposant sur la capacité qu'a un sous-programme de se rappeler lui-même, les sous-programmes récursifs sont les plus sujets à provoquer de tels débordements. Il faut donc agir avec prudence.
Note historique : certains langages de programmation qu'on oserait qualifier d'anciens (FORTRAN77 par exemple, de même que plusieurs versions de COBOL) ne permettaient pas de déclarer de véritables variables locales à un sous-programme, ce qui rendait la récursivité pénible dans ces langages, celle-ci devant alors être implémentée manuellement.
Les compilateurs (et les calculatrices!) ont souvent à analyser des expressions mathématiques, comme par exemple :
Ces exemples sont limités à des opérations arithmétiques simples et usuelles binaires (au sens de à deux opérandes), mais tout ce qui sera exprimé ici pourrait être étendu à la gamme entière des opérateurs, incluant les opérateurs unaires (à un opérande) et l'affectation.
Ces expressions doivent pouvoir être représentées et évaluées efficacement par un compilateur (ou par un programme tout court), de manière à ce que les priorités des opérateurs et les parenthèses soient respectées.
L'une des manières les plus répandues de représenter ces expressions est sous forme d'arbres. Sans entrer dans les détails (ce serait un peu lourd pour une discussion sur la récursivité) :
Dans nos arbres, une feuille contiendra une valeur numérique et tout noeud qui n'est pas une feuille contiendra un opérateur (nos opérateurs seront tous binaires, mais ce n'est pas une exigence du modèle; nous voulons simplement garder le tout le plus simple possible).
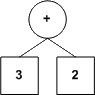
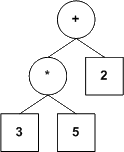
Voici ce dont pourraient avoir l'air les représentations en arbre des expressions arithmétiques proposées plus haut.
| Expression | ||||||
|---|---|---|---|---|---|---|
| Arbre correspondant |  |
 |
 |
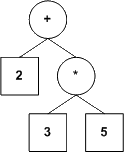 |
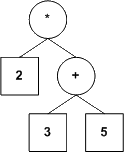 |
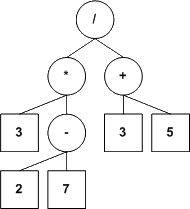 |
Un algorithme récursif est la manière la plus naturelle d'explorer de telles structures. Pour en faire la démonstration, examinons la méthode valeur() de la classe Noeud ci-dessous, en tenant compte que :
struct Noeud {
Noeud *gauche {},
*droite {};
bool feuille() const noexcept {
return !gauche && !droite;
}
//
// Méthodes abstraite qui seront spécialisées pour les opérateurs et pour les opérandes
//
virtual int valeur() const = 0;
virtual bool est_valide() const = 0;
Noeud() = default;
void clear() {
if (!feuille()) {
gauche->clear();
delete gauche;
gauche = {};
droite->clear();
delete droite;
droite = {};
}
}
};
class NoeudValeur : public Noeud {
int val;
public:
NoeudValeur(int val) : val{ val } {
}
int valeur() const {
return val;
}
bool est_valide() const {
return feuille();
}
};
struct NoeudOperateurBinaire : Noeud {
bool est_valide() const {
return gauche && droite;
}
}
struct NoeudSomme : NoeudOperateurBinaire {
int valeur() const {
return gauche->valeur + droite->valeur;
}
};
struct NoeudDifference : NoeudOperateurBinaire {
int valeur() const {
return gauche->valeur - droite->valeur;
}
};
struct NoeudProduit : NoeudOperateurBinaire {
int valeur() const {
return gauche->valeur * droite->valeur;
}
};
class div_par_zero {};
struct NoeudQuotient : NoeudOperateurBinaire {
int valeur() const {
auto denom = droite->valeur;
if (!denom) throw div_par_zero{};
return gauche->valeur / denom;
}
};Notez que les méthodes requises pour valider chaque Noeud sont implémentées mais n'ont pas été utilisées pour simplifier le propos. Notez aussi que le code requis pour construire un arbre n'a pas été fourni, pour que notre regard demeure porté sur l'essentiel, mais sentez-vous bien à l'aise de rédiger ce code si l'envie vous en prend!
Clin d'oeil mis en place par des gens à l'humour subtil : voir ceci
Si la question vous intéresse, le sujet de la récursivité est vaste, c'est le moins qu'on puisse dire. Vous trouverez ici une courte liste (vraiment rien qui ait la prétention d'être exhaustif!) de lectures complémentaires :
